This study investigated methods for efficiently generating voice clones from a small amount of speech data.
Voice cloning is a technology that records a person’s voice and reproduces it through machine learning, and it has been widely applied in systems such as Vocaloid and recent AI-based voice generation tools(Figure1).
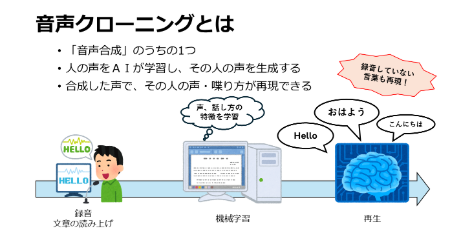
However, conventional approaches often require large amounts of recordings and complex processes, making them difficult for non-specialists to handle. To address this issue, this study employed Tacotron2, a speech synthesis model, to examine the quality of voice clones produced with minimal voice data.
Specifically, 20 sentences were recorded by four participants and used for training. The generated speech was extracted at different training stages and evaluated on a five-point scale using original criteria. The results showed that after 5,000 training iterations, the average score reached 3.36, representing the highest quality, and that the quality of the generated voice improved as the number of training iterations increased(Table1).
Future work will focus on refining the selection of recording sentences and developing a fully automated system to achieve faster and higher-quality voice cloning.
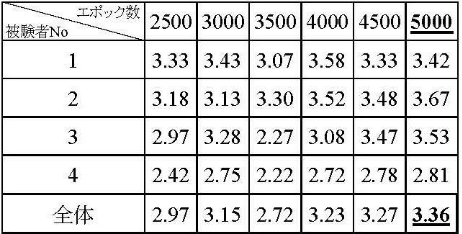
Table1. The average score of the voice clone for each training epoch