本研究では、大規模言語モデル(LLM)によって自動生成されたプログラムの品質を、ソースコードのステップ数や複雑度などのコードメトリクスと静的解析ツールを適用し、品質状況を調査しました。近年、ChatGPTに代表されるLLM はプログラミング支援能力を備え、開発効率や保守性の向上への活用が期待されています。しかし自動生成コードには、不要な変数や条件分岐が含まれる場合もあり、その品質状況の調査が現状十分とは言えません。
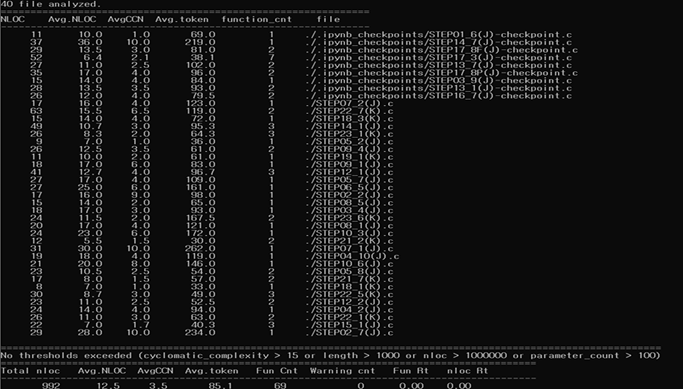
そこで本研究では、40件のC言語のプログラミング問題をChatGPTに生成させて、得られたソースコードを静的解析ツールLizardにより循環的複雑度(CCN)を分析しました。
| CCN | 目安 |
| 1~10 | シンプルで理解しやすいプログラム |
| 11~20 | 若干複雑なプログラム |
| 21~ | 複雑なプログラムであり、完全に理 解してテストを作成するのが困難 |
| 50〜 | 保守困難、バグが確実に潜在するプログラム |
結果として、正解したソースコードは32問で正答率は80%、さらに全てのコードのCCNの値が10以下と低い複雑度であり、可読性の高いコードが生成されることが確認されました。これらの結果から、LLMを用いた自動プログラミングは、開発速度の向上、品質の向上、保守性の向上、コストの削減などの多くの利点が期待できます。